Monge 行列と monotone minima について
Monge 行列や monotone minima について何も知らない方でも理解できるよう, 一から丁寧に解説する記事を書きました. 計算量解析については多少の前提知識を要求しますが, その他の部分については式を追っていけば理解できると思います.
本記事の評判次第ではありますが, 続編として SMAWK algorithm についての記事もいずれ書きたいと考えております.
Monge 行列の定義と性質
定義
$ m \times n $ 型実数値行列 $ A $ が, $ 1 \leq i \lt k \leq m $ および $ 1 \leq j \lt l \leq n $ を満たすすべての $ i, j, k, l $ について
A[i, j] + A[k, l] \leq A[i, l] + A[k, j]
を満たすとき, $ A $ を Monge 行列と呼ぶ.
つまり, Monge 行列から任意に 2 つの行と 2 つの列を取り, それらの行と列の交点で定まる 4 つの要素を考えたとき, 左上と右下の要素の和は左下と右上の要素の和以下である.
たとえば, 以下に示す行列は Monge 行列である.
\left(
\begin{matrix}
10 \quad 17 \quad 13 \quad 28 \quad 23\\
17 \quad 22 \quad 16 \quad 29 \quad 23\\
24 \quad 28 \quad 22 \quad 34 \quad 24\\
11 \quad 13 \quad \ \ 6 \quad 17 \quad \ \ 7\\
45 \quad 44 \quad 32 \quad 37 \quad 23\\
36 \quad 33 \quad 19 \quad 21 \quad \ \ 6\\
75 \quad 66 \quad 51 \quad 53 \quad 34\\
\end{matrix}
\right)
補題 1
ある $ m \times n $ 型行列 $ A $ が Monge 行列であるための必要十分条件は, $ 1 \leq i \lt m $ および $ 1 \leq j \lt n $ を満たすすべての $ i, j $ について
A[i, j] + A[i+1, j+1] \leq A[i, j+1] + A[i+1, j]
が成立することである.
証明
$ (\Rightarrow) $
Monge 行列の定義より明らかである.
$ (\Leftarrow) $
$ 1 \leq s \lt m $ および $ 1 \leq t \lt n $ を満たすすべての $ s, t $ について
A[s, t] + A[s+1, t+1] \leq A[s, t+1] + A[s+1, t]
であるとき, $ 1 \leq i \lt k \leq m $ を満たす $ i, k $ について $ s = i, \ldots, k - 1 $ として辺々加えて,
両辺ともに出現する項を消去し,
A[i, t] + A[k, t+1] \leq A[i, t+1] + A[k, t].
次に, $ 1 \leq j \lt l \leq n $ を満たす $ j, l $ について $ t = j, \ldots, l - 1 $ として辺々加えて, 式を整理すると,
A[i, j] + A[k, l] \leq A[i, l] + A[k, j].
以上より, $ A $ が Monge 行列であることが示された.
補題 2
$ f(i) $ を, 行 $ i $ の最小要素のうち最も左に位置するものの列番号とする. 任意の $ m \times n $ 型 Monge 行列において
f(1) \leq f(2) \leq \cdots \leq f(m)
が成り立つ.
証明
$ A $ を $ m \times n $ 型 Monge 行列として, $ 1 \leq i \lt m $ かつ $ f(i) \gt f(i + 1) $ を満たす $ i $ が存在すると仮定する.
$ A $ は Monge 行列であることから,
A[i, f(i + 1)] + A[i + 1, f(i)] \leq A[i, f(i)] + A[i + 1, f(i + 1)]\tag{1}
が成り立つ.
一方, $ f(i) $ は行 $ i $ における最左の最小要素の列番号であるため,
A[i, f(i + 1)] \gt A[i, f(i)].
$ f(i + 1) $ は行 $ i + 1 $ における最左の最小要素の列番号であるため,
A[i + 1, f(i)] \geq A[i + 1, f(i + 1)].
辺々加えて,
A[i, f(i + 1)] + A[i + 1, f(i)] \gt A[i, f(i)] + A[i + 1, f(i + 1)]\tag{2}
を得る.
式 $(1), (2)$ が同時に成り立つことはないため, $ 1 \leq i \lt m $ かつ $ f(i) \gt f(i + 1) $ を満たす $ i $ は存在しない.
以上より, 任意の $ m \times n $ 型 Monge 行列において
f(1) \leq f(2) \leq \cdots \leq f(m)
が成り立つことが示された.
補足
なお, $ m \times n $ 型行列 $ A $ について
f(1) \leq f(2) \leq \cdots \leq f(m)
が成り立つことを, monotone であるという.
さらに, $ A $ の任意の部分行列*1について monotone であるとき, $ A $ は totally monotone であるという.
Monge 行列が monotone であることは補題 2 で示しており, $ A $ が Monge 行列であるとき, $ A $ の任意の部分行列も明らかに Monge 行列であるので, 任意の Monge 行列は totally monotone である.
つまり, 「$ A $ が Monge 行列 $ \Rightarrow $ $ A $ は totally monotone $ \Rightarrow $ $ A $ は monotone」という関係が成り立っており, $ A $ が Monge 行列であることは totally monotone であることや monotone であることよりも"強い"条件であるといえる.
monotone minima
monotone minima とは, monotone な行列について各行の最小要素のうち最も左に位置するものの列番号, すなわち補題 2 における $ f(i) $ を効率よく求める分割統治アルゴリズムである.
アルゴリズムの解説
$ A $ を $ m \times n $ 型の monotone な行列とする. monotone minima の概要は以下の通りである.
- $ A $ の偶数行だけ取り出して $ A $ の部分行列 $ A' $ を作る.
- $ A' $ に対して再帰的にアルゴリズムを適用し, 各行における最左の最小要素の列番号を求める.
- $ A $ の奇数行における最左の最小要素の列番号を求める.
まず, $ A $ の偶数行の最左の最小要素の列番号が分かっているという仮定のもとで, $ A $ の奇数行の最左の最小要素の列番号を $ O(m+n) $ 時間で求める方法を解説する.
番兵として $ f(0) = 1, f(m+1) = n $ と定義すると, $0 \leq k \lt \left\lceil m/2 \right\rceil $ を満たす $ k $ に対して $ f(2k+1) $ を求めるには, $ A $ が monotone であることより, $ 2k+1 $ 行目の $ f(2k) $ 列目から $ f(2k+2) $ 列目までを線形探索すればよい.
$ 1 \leq j \leq n $ を満たす各 $ j $ に対して, $ 1 \leq i \leq m $ かつ $ f(i) = j $ を満たす偶数 $ i $ の個数を $ N _ j $ と表すと, $ j $ 列目の数が探索される回数は $ N _ j + 1 $ 回である. $ \sum _ {j=1} ^ {n}{N_j} = \left\lfloor m/2 \right\rfloor $ であることに注意し, 合計探索回数は $ \sum _ {j=1} ^ {n}{\left( N_j + 1 \right)} = \left\lfloor m/2 \right\rfloor + n $ と求められる.
以上より, ステップ 3. の時間計算量が $ O(m + n) $ であることが示された.
次に, このアルゴリズム全体の時間計算量を解析する.
$ m \times n $ 型の行列に対して monotone minima を適用したときの最悪実行時間を $ T(m, n) $ とおく. 再帰のベースケースとして $ m = 1 $ のときの最悪実行時間は $ O(n) $ であり, $ m \times n $ 型行列に対する問題は $ \left\lfloor m/2 \right\rfloor \times n $ 型行列に対する問題と $ O(m+n) $ 時間の処理に帰着されるので, 以下の漸化式が得られる.
\left\{
\begin{aligned}
T(1, n) &= O(n), \\
T(m, n) &= T(\left\lfloor m/2 \right\rfloor, n) + O(m + n). \\
\end{aligned}
\right.
よって, ある定数 $ c _ 1 , c _ 2 > 0 $ が存在して, すべての $ m, n $ について以下の不等式が成り立つ.
\left\{
\begin{aligned}
T(1, n) &\leq c _ 1 n, \\
T(m, n) &\leq T(\left\lfloor m/2 \right\rfloor, n) + c _ 2(m + n). \\
\end{aligned}
\right.
\tag{3}
この漸化式の解を $ T(m, n) = O(m + n \lg{m}) $ であると推定する. *2
ここで $ c $ を, すべての $ n $ について以下の条件を満たすようにとる.
\left\{
\begin{aligned}
c_2 &\leq \frac{1}{2}c, \\
T(2, n) &\leq c(2 + n\lg{2}), \\
T(3, n) &\leq c(3 + n\lg{3}). \\
\end{aligned}
\right.
そのような $ c $ の存在は, 式 $(3)$ に従い $T(2, n), T(3, n)$ を変形すれば示せる.
以下, すべての $m \geq 2, n $ について $ T(m, n) \leq c(m + n \lg{m})$ が成り立つことを帰納法で示す.
$ m = 2, 3 $ のとき, $ c $ の定義より明らか.
$ m \geq 4$ のとき,
\begin{aligned}
T(m, n) &\leq T\left(\left\lfloor \frac{m}{2} \right\rfloor, n\right) + c_2(m + n)\\
&\leq c\left(\left\lfloor \frac{m}{2} \right\rfloor + n \lg{\left\lfloor \frac{m}{2} \right\rfloor}\right)+ c _ 2(m + n) \\
&\leq c\left(\frac{m}{2}+ n \lg\frac{m}{2}\right)+ c _ 2(m + n) \\
&\leq c\left(\frac{m}{2} + n \lg\frac{m}{2}\right)+ \frac{1}{2}cm + cn \\
&\leq c(m + n \lg{m}).\\
\end{aligned}
以上より, ある定数 $ c > 0 $ が存在して, すべての $m \geq 2, n$ に対して $ T(m, n) \leq c(m + n \lg{m})$ が成り立つ.
したがって, アルゴリズム全体の時間計算量は $ O(m + n \lg{m}) $ である.
補足
本記事で紹介した monotone minima のアルゴリズムは, Monotone minima | Kyopro Encyclopedia of Algorithms においてその他の変種として扱われているものに相当する.
ただし, 本記事で紹介した monotone minima のアルゴリズムはより発展的なアルゴリズムである SMAWK algorithm のサブルーチンに相当するため, 今後 SMAWK algorithm についての記事を執筆することを念頭に置き, 変種として扱われている方を解説することとした.
実装例
実装上, 行列 $ A $ を陽に保持すると, それだけで空間計算量が $ \Theta (mn)$ となり, それに伴い時間計算量も $ \Omega (mn)$ となってしまうため, $ A $ は陰に保持されるべき*3である点に注意を要する.
引数 select の定義は,
select(i, j, k) $ := $ $ A[i, j] $ と $ A[i, k] $ $ (j < k) $ を比較して, 前者を選ぶ場合 false , 後者を選ぶ場合true
としている.
なお, 以下の実装方針は熨斗袋 (@noshi91) さんの SMAWK Algorithm の実装を参考にした.
#include <functional> #include <numeric> #include <vector> template <class Select> std::vector<size_t> monotone_minima(const size_t row_size, const size_t col_size, const Select& select) { using vec_zu = std::vector<size_t>; const std::function<vec_zu(const vec_zu&)> solve = [&](const vec_zu& row) -> vec_zu { const size_t m = row.size(); if (m == 0) return {}; vec_zu row2; for (size_t i = 1; i < m; i += 2) row2.push_back(row[i]); const vec_zu ans2 = solve(row2); vec_zu ans(m); for (size_t i = 0; i < ans2.size(); ++i) ans[2 * i + 1] = ans2[i]; size_t j = 0; for (size_t i = 0; i < m; i += 2) { ans[i] = j; const size_t end = (i + 1 == m ? col_size - 1 : ans[i + 1]); while (j != end) { j++; if (select(row[i], ans[i], j)) ans[i] = j; } } return ans; }; vec_zu row(row_size); std::iota(row.begin(), row.end(), 0); return solve(row); }
例題
読者への課題とする.
atcoder.jp
ヒント↓ (反転せよ.)
行列 $ A $ を
$ A[i, j] := i $ 番のすぬけキャノンでけぬす号の区画 $ j $ を破壊するために必要なエネルギー
と定義すると, $ A $ はどのような性質を持つか.
参考リンク
- Monotone minima | Kyopro Encyclopedia of Algorithms
- SMAWK Algorithm | Library
- Totally Monotone Matrix Searching (SMAWK algorithm) - 週刊 spaghetti_source - TopCoder部
参考文献
- Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to algorithms. MIT press, 2009.
謝辞
本記事公開前に, えびちゃん (@rsk0315_h4x) さんにレビューと校正をしていただきました. また, monotone minima の時間計算量の解析について, 熨斗袋 (@noshi91) さんにご教授いただきました. ありがとうございました.
*1:https://ja.wikipedia.org/wiki/%E5%B0%8F%E8%A1%8C%E5%88%97
*3:$i, j$ を渡すと $ A[i, j] $ の値を返す関数が用意されている状況などを想定されたい.
ICPC 2020 Asia Yokohama Regional 参加記
Lorent、xelmeph、nrkt の3人で名古屋大学チーム XENT として ICPC 2020 Asia Yokohama Regional に参加しました。
チーム紹介や国内予選につきましては、ぜひ以下の記事をお読みいただけると嬉しいです。 lorent-kyopro.hatenablog.com
Contest
私の動きだけ簡潔に書きます。
開始直後、B を xelmeph さんに任せて、A を nrkt さんと一緒に読みました。サクッと考察を済ませて C 以降を読みにいくつもりだったものの、解法が浮かばずかなり時間をかけてしまった上に、 nrkt さんに嘘考察を伝えて実装をお願いしてしまいました。
C〜E を読んで問題概要を軽くまとめたところで、A で WA が出てしまい、急遽考察し直しに戻ります。 少し冷静になれたのか、なんとか正しい解法を導き出すことができ、改めて nrkt さんに実装をお願いしました。
F 以降の問題を読み進めていると B の考察・実装を終えた xelmeph さんがデバッグに苦戦しているとのことだったので、xelmeph さんの書いた B のコードを眺めたところ、必要のなさそうな条件分岐を見つけて削除したら無事 AC。チームデバッグがうまくいき、A の嘘考察の借りは少し返せたかなと気を取り直しました。
この時点で J がかなり解かれていた上に xelmeph さんの得意そうな木の問題だったので、「xelmeph さんなら解けると思います」と言って投げました。
A の実装中の nrkt さんから「添字で頭を壊しています」と言われ、デバッグのヘルプに向かいます。添字を丁寧に調節して AC。どうやら今日の私はデバッグ力が冴えているようです。
その後、J はだいたいこんな感じの DFS すればいけそうという方針を xelmeph さんが立ててくれたところから、細部を詰めるのに協力していました。結局 AC までにかなり時間かかっちゃいました。この時点で開始から 2 時間 35 分です。
残り約 2 時間半、主には G の考察・実装を進めていました。DSU で連結成分数を管理するだとか、条件式だとか、いいところまで考察を伸ばせていたにも関わらず、結局最後まで通せず本当に悔しかったです。
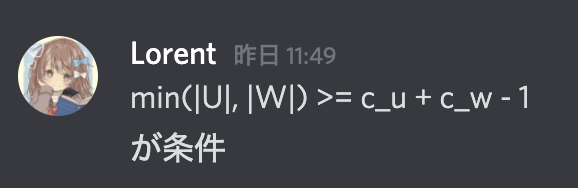
他の問題の感想です。
D は最初読んだときはそれほど難しい問題に見えなくて、「解きたい見た目してる」とか言っていました。最終的にはチーム ___ KING ___ しか通せなかった問題で、今考えるととても恥ずかしいですね。
H について、始まる前にチームメイトに「クエリ問は解きたい」と宣言していたにも関わらず全く解法が見えず。
I は明らかに箱根駅伝 DP だよねとチームで話してはいたものの、細部を詰められず。
最終結果は 40 チーム中 37 位でした。

Closing Party
Gather、すごかったです。オンラインで交流なんて……とか初めは思っていましたが、歩き回って出会った方々とお話しする感覚は実際の懇親会にもかなり近いものに感じましたし、もしかしたら実際の懇親会では気が引けて話しかけられなかったかもしれない方々とも、オンラインだからこそお話しできたのかもしれないなと思います。
コンテスト直後 Gather に入って少し緊張しているときにチーム tsutaj さんの輪に入れてもらって楽しく雑談できたり、チーム UHISHIRO さん、onions さんの輪に入れてもらって一緒に解説を聞きながら問題の感想を言い合ったり、プライベートルームでえびちゃんさんとお話ししていたらJAG の方々に出口を塞がれた上での熱烈勧誘を受けたり、みさわ先生のフローのプチ講義を聞けたり、チーム eat_ice の潜伏に対してジャッジ側がシステムトラブルを疑って焦っていたという裏話を聞けたり、チーム appeared のしんちゃんさんとチームメイトとの相性についての談義をしたり、私が競プロをはじめた頃から Twitter で仲良くさせていただいている ntk さんと長話できたり、stoq さんに全方位木 DP の記事にお世話になった旨を直接お伝えできたり……まだまだここには書ききれないほどたくさんの方々とお話しできました。交流してくださった方は本当にありがとうございました。
感想
コンテストに関しては、私たちなりにはやりきれたとも言い難いほど情けない成績でした。国内予選終了後に立てた目標の「あと一問の壁を超える」も達成できず、悔しかったです。本番の動きに大きな反省点があるというよりは、正直私たちの実力では到底太刀打ちできないほど高いレベルの争いだったように感じます。来年もっと強くなって戻ってきたい……と言いたいところなんですが、年齢的に、これで私の最初で最後の ICPC への挑戦は終わってしまいました。
ここまで一緒に戦ってくれたチームメイトの 2 人には感謝しかありません。ありがとうございました。私が誘っておきながら、もっと強くなると言っておきながら、最後の最後まで弱いままで申し訳ありませんでした。
私が競プロに取り組む大きな理由の 1 つであった ICPC はこれでおしまいです。今回のコンテストを通して、トップ競プロ er の方々に少しでも近づきたいという思いを強く抱いたものの、最近は少し競プロ疲れのようなものも感じてしまっています。ここを一つ気持ちの区切りとして、また改めて私なりのペースで、競プロを嫌いにならない程度にぼちぼち続けていきたいなと思います。
Dynamic Segment Tree の ACL 風実装
インターフェースを ACL ( AtCoder Library ) に寄せた Dynamic Segment Tree を書きました。
Dynamic Segment Tree の概要
そこらに生えている多くのセグ木は、事前に適切なサイズの配列を確保した上で、二分ヒープ的 index で親や子に移動するような実装となっていますね。そういったセグ木で、例えば以下のようなクエリは捌けるでしょうか。
すベて
で初期化された長さ
の数列
があります。
以下で説明されるクエリを回、オンラインで処理してください。クエリは 2 種類あります。
クエリ 1:
が与えられるので、
に
を加算する。
クエリ 2:が与えられるので、
を報告する。
ただし
である。
注目すべきは の制約です。二分ヒープ的な index で管理する、いわゆる通常のセグ木で処理しようとすると、一般的なメモリ制限では MLE となります。また、オンライン処理なので、クエリ先読みした上での座標圧縮もできません。
ところで、セグ木の一回のクエリ処理でアクセスするノードの数は なので、実は上述のクエリを処理するためには
のノードがあれば十分足りてしまいます。(本問の最大ケースでも
程度です。)
つまり、必要になったときに初めてそのノードを作るような実装にすれば、MLE することなく上述のクエリも処理できてしまいます。こういった実装の工夫がなされたセグ木のことを Dynamic Segment Tree と呼んでいます。(呼称については controversial です。私は「必要な部分だけ作るセグ木」という呼び方が好きですが、これはこれで簡潔ではありませんし、Codeforces のブログ等でも「Dynamic Segment Tree」という呼称が用いられているため、検索でのヒットのし易さ等も考慮して本記事では「Dynamic Segment Tree」で統一します。)
以下のリンク先の説明が簡潔にまとまっていておすすめです。
scrapbox.io
Dynamic Segment Tree の長所・短所
長所
- 実際に必要となるノード数が十分小さければ、大きなサイズの数列に対するクエリも、先読みや座標圧縮をすることなく処理することができる。
短所
- 通常のセグ木と比較してメモリアクセスが遅い。
- 一点取得の時間計算量は、通常のセグ木では
であるのに対して、Dynamic Segment Tree では
となる。
- 基本的には初期化は単位元でしか行えない。(工夫すれば、単位元以外の値での初期化もできます。)
実装についての簡単な説明
ポインタを用いて実装します。多少書き慣れていないと少し理解するのが難しいかもしれません。ポインタを用いてデータ構造を書いた経験がない方は、まずは AOJ ALDS1 #8 を書いてみるのがおすすめです。
Dynamic Segment Tree はポインタを用いて書く関係上、全ての処理がトップダウン的になります。再帰セグ木に近い構造です。
まずは抽象化はしていない、シンプルな一点更新区間和取得 Dynamic Segment Tree の実装を見ていきましょう。主に通常のセグ木と異なる部分について、コード中にコメントを入れています。
#include <cstddef> class dynamic_segtree { public: // 初め、 root は nullptr となっている dynamic_segtree(size_t n) : n(n), root(nullptr) {} void set(size_t p, int x) { set(root, 0, n, p, x); } int get(size_t p) { return get(root, 0, n, p); } int prod(size_t l, size_t r) { return prod(root, 0, n, l, r); } private: // 各 node に、値と左右の子のポインタを持たせる struct node { int value; node* left; node* right; // 初め、左右の子は nullptr となっている node(int value) : value(value), left(nullptr), right(nullptr) {} }; size_t n; // セグ木の根のポインタを管理する node* root; void set(node*& t, size_t a, size_t b, size_t p, int x) { // そのノードがまだ作られていなかったら作る if (!t) t = new node(0); // 区間幅が 1、つまりセグ木の葉にたどり着いたら値を更新 if (b - a == 1) { t->value = x; return; } // それ以外の場合は左か右の子に進む size_t c = (a + b) >> 1; if (p < c) set(t->left, a, c, p, x); else set(t->right, c, b, p, x); // ノードの値の更新(左右の子が作られていない可能性があることに注意) t->value = 0; if (t->left) t->value += t->left->value; if (t->right) t->value += t->right->value; } // set とほぼ同じ int get(node*& t, size_t a, size_t b, size_t p) { if (!t) return 0; if (b - a == 1) return t->value; size_t c = (a + b) >> 1; if (p < c) return get(t->left, a, c, p); else return get(t->right, c, b, p); } int prod(node*& t, size_t a, size_t b, size_t l, size_t r) { // ノードが作られていない、もしくは区間の重なりがなければ、単位元を返す if (!t || b <= l || r <= a) return 0; // クエリ区間がノード区間を包含していれば、そのノードの持つ値を返す if (l <= a && b <= r) return t->value; // それ以外の場合は、左右の子に進む size_t c = (a + b) >> 1; return prod(t->left, a, c, l, r) + prod(t->right, c, b, l, r); } };
再帰セグ木をご存知でしたら理解は容易かと思います。private 内void set(t, a, b, p, x)の一番初め、アクセスした時にそのノードがまだなかったら作る行が、Dynamic Segment Tree の肝中の肝です。
基本的な実装方針としては以上の通りなのですが、下記の実装コードでは、void set(t, a, b, p, x)のノード作成時に、 が成り立つまでノードを作成し続けるのではなく、子が一つだけで葉まで続く部分は省略してノードの作成数を押さえる工夫を加えています。これにより、元々は一点更新クエリ毎に新しく作成されるノード数が
だったものを高々1個まで減らすことができるため、一点更新クエリの回数を
回として、空間計算量を
から
に改善することができます。
この工夫についての詳細は kazuma8128 さんのブログをご覧ください。 kazuma8128.hatenablog.com
実装コード
抽象化して、さらにstd::unique_ptrを使いより安全なメモリ確保を行うようにしたものです。public の部分を見るとわかるように、ACL の segtree と使い方はほぼ同じです。みんな使ってね。
※ 2021/3/28
ある区間を単位元に戻す(いらないノードを削除する)関数 reset と
セグ木上の二分探索 max_right, min_left を追加しました。
#include <cassert> #include <cstddef> #include <memory> #include <utility> template <class S, S (*op)(S, S), S (*e)()> class dynamic_segtree { public: dynamic_segtree(size_t n) : n(n), root(nullptr) {} void set(size_t p, S x) { assert(p < n); set(root, 0, n, p, x); } S get(size_t p) const { assert(p < n); return get(root, 0, n, p); } S prod(size_t l, size_t r) const { assert(l <= r && r <= n); return prod(root, 0, n, l, r); } S all_prod() const { return root ? root->product : e(); } void reset(size_t l, size_t r) { assert(l <= r && r <= n); return reset(root, 0, n, l, r); } template <bool (*f)(S)> size_t max_right(size_t l) const { return max_right(l, [](S x) { return f(x); }); } template <class F> size_t max_right(size_t l, const F& f) const { assert(l <= n); S product = e(); assert(f(product)); return max_right(root, 0, n, l, f, product); } template <bool (*f)(S)> size_t min_left(size_t r) const { return min_left(r, [](S x) { return f(x); }); } template <class F> size_t min_left(size_t r, const F& f) const { assert(r <= n); S product = e(); assert(f(product)); return min_left(root, 0, n, r, f, product); } private: struct node; using node_ptr = std::unique_ptr<node>; struct node { size_t index; S value, product; node_ptr left, right; node(size_t index, S value) : index(index), value(value), product(value), left(nullptr), right(nullptr) {} void update() { product = op(op(left ? left->product : e(), value), right ? right->product : e()); } }; const size_t n; node_ptr root; void set(node_ptr& t, size_t a, size_t b, size_t p, S x) const { if (!t) { t = std::make_unique<node>(p, x); return; } if (t->index == p) { t->value = x; t->update(); return; } size_t c = (a + b) >> 1; if (p < c) { if (t->index < p) std::swap(t->index, p), std::swap(t->value, x); set(t->left, a, c, p, x); } else { if (p < t->index) std::swap(p, t->index), std::swap(x, t->value); set(t->right, c, b, p, x); } t->update(); } S get(const node_ptr& t, size_t a, size_t b, size_t p) const { if (!t) return e(); if (t->index == p) return t->value; size_t c = (a + b) >> 1; if (p < c) return get(t->left, a, c, p); else return get(t->right, c, b, p); } S prod(const node_ptr& t, size_t a, size_t b, size_t l, size_t r) const { if (!t || b <= l || r <= a) return e(); if (l <= a && b <= r) return t->product; size_t c = (a + b) >> 1; S result = prod(t->left, a, c, l, r); if (l <= t->index && t->index < r) result = op(result, t->value); return op(result, prod(t->right, c, b, l, r)); } void reset(node_ptr& t, size_t a, size_t b, size_t l, size_t r) const { if (!t || b <= l || r <= a) return; if (l <= a && b <= r) { t.reset(); return; } size_t c = (a + b) >> 1; reset(t->left, a, c, l, r); reset(t->right, c, b, l, r); t->update(); } template <class F> size_t max_right(const node_ptr& t, size_t a, size_t b, size_t l, const F& f, S& product) const { if (!t || b <= l) return n; if (f(op(product, t->product))) { product = op(product, t->product); return n; } size_t c = (a + b) >> 1; size_t result = max_right(t->left, a, c, l, f, product); if (result != n) return result; if (l <= t->index) { product = op(product, t->value); if (!f(product)) return t->index; } return max_right(t->right, c, b, l, f, product); } template <class F> size_t min_left(const node_ptr& t, size_t a, size_t b, size_t r, const F& f, S& product) const { if (!t || r <= a) return 0; if (f(op(t->product, product))) { product = op(t->product, product); return 0; } size_t c = (a + b) >> 1; size_t result = min_left(t->right, c, b, r, f, product); if (result != 0) return result; if (t->index < r) { product = op(t->value, product); if (!f(product)) return t->index + 1; } return min_left(t->left, a, c, r, f, product); } };
実行時間比較
の 3 つの実行時間の比較を行いました。
| 実行時間 ( 10回平均と95%信頼区間 ) | |
|---|---|
| 1. Dynamic Segment Tree | 75.0 ± 3.0 ms |
| 2. Segtree ( ACL ) | 55.3 ± 1.3 ms |
| 3. Fenwick Tree ( ACL ) | 50.3 ± 0.5 ms |
本記事の Dynamic Segment Tree は他の 2 つに比べると多少遅いですが、クエリをオンラインで処理できるという点ではえらいですね。
問題例
- AtCoder Regular Contest 008 D - タコヤキオイシクナール
の関数列に対するクエリを扱えると座標圧縮をせずにすむので少し楽になります。 atcoder.jp
(Dynamic Segment Tree が使いたくなる他の問題例も募集中です!)
コード貼り付けただけのブログしかあげられない人生
— Lorent (@lorent_kyopro) 2021年3月11日
k番目に小さい値を簡単に取得するよ(C++)
まずはおまじないを書いて……
#include <ext/pb_ds/assoc_container.hpp> using namespace __gnu_pbds; template<typename T> using ordered_set = tree<T, null_type, std::less<T>, rb_tree_tag, tree_order_statistics_node_update>;
こう。
#include <iostream> int main() { ordered_set<int> s; s.insert(1); s.insert(2); s.insert(4); s.insert(8); s.insert(16); // find_by_order : 0-indexed で k 番目に小さい値を指すイテレータを取得する // O(log(n)) std::cout << *s.find_by_order(1) << std::endl; // 2 std::cout << *s.find_by_order(2) << std::endl; // 4 std::cout << *s.find_by_order(4) << std::endl; // 16 std::cout << (s.end() == s.find_by_order(6)) << std::endl; // true // おまけ // order_of_key : x 未満である要素数を取得する // O(log(n)) std::cout << s.order_of_key(-5) << std::endl; // 0 std::cout << s.order_of_key(1) << std::endl; // 0 std::cout << s.order_of_key(3) << std::endl; // 2 std::cout << s.order_of_key(4) << std::endl; // 2 std::cout << s.order_of_key(400) << std::endl; // 5 }
座標圧縮して Fenwick Tree 上の二分探索して元の値を復元して……とかちょっと面倒なことをしなくて済むね。
こういう問題が殴れちゃいます。
多重集合を扱いたいときは、std::pairをのせて、値と一緒にユニークなIDを持たせればよいです。
こんな感じ。
参考資料
C++ STL: Policy based data structures - Codeforces
以上でした。ありがとうございました。
ICPC 2020 国内予選参加記
チーム結成
6/22のこのツイートから、私にとっては最初で最後のICPCへの挑戦が始まりました。
せっかくまだ大学生なので、ICPC国内予選だけでも経験してみたいな
— Lorent (@lorent_kyopro) 2020年6月21日
TLの弊大生、私とチーム組んでくださる方いらっしゃいませんか
これを見たnrktさんからすぐにDMをいただき、さらに私の方からxelmephさんにオファーしたら快諾していただけたため、その日のうちにチームが結成できてしまいました。便利な時代になりましたね。
同学の私より全然強い方に、ICPC一緒に出ていただけないかお願いしたところ快諾いただけた…ありがたみの極み…
— Lorent (@lorent_kyopro) 2020年6月22日
チーム名は「XENT」になりました。込められた意味については以下です。
ちょっと早いですが、
— Lorent (@lorent_kyopro) 2020年11月4日
ICPC国内予選は@Xelmhと@nrkt13と私の3人でXENTとして出場します
チーム名はメンバーそれぞれのAtCoderアカウント名の文字を抜き出して組み合わせたものですが、愛知のパチンコチェーン「ZENT」ともかけています
対戦よろしくお願いします🔥https://t.co/zZTBazTOFL
チームメンバー紹介
nrktさん
国内予選時AtCoder水色。Pythonista。今回ICPC初参加。コミュ力が高そう、というか高い。実装が丁寧な印象。序盤の問題をペナを出さず安定した速度で埋めてくれて、チームに安心感をもたらす。後半は考察側に回り、ひたすら考えてくれる。私の考えた嘘解法を落とすサンプルケースを作るのが得意。ありがとうございます。
xelmephさん
国内予選時AtCoder青色。C++er。過去2回ICPC国内予選参加経験あり。PC周りの知識がかなりありそう。C++を理解している人が書きそうなコードを書く。グラフ系の問題が得意。万物からグラフ構造を見出せる特殊能力を持っているので「あーこれDAGになってるね」とかいきなり言い出すのだが、私はいつも理解が追いつけない。すごい。
本番前日
ICPC国内予選のジャッジは、テストケースをダウンロードし、ローカルでプログラムを実行して出力されたファイルを提出するという形で行われるので、想定解よりも時間計算量が多少悪くても、動いてしまえば勝ちです。
ルール改定により事前に準備したコードの貼り付けがOKになったことを存分に活用しようということで、xelmephさんがstd::mutexを使った並列処理のテンプレを準備していました。

(まさかこの事前準備に救われることになろうとは、この時点では全く思っていませんでした……!)
本番
チーム練は主にオンラインでしていたのですが、やはり考察の共有やお互いの状況確認が容易との理由から、本番は大学のゼミ室を借りてそこに集まることとなりました。
当日16時頃に3人揃い、本番まで少しだけ作戦会議。練習でやってきた通りまずはAをnrktさん、Bを私、Cをxelmephさんが解くこと、わからなくなったらすぐ周りにHELPを求めること、「多分こうだろう」という考察をしてしまった部分を前提だと思い込まないように気を付けること、幾何や実装ゲーはxelmephさんに投げること、構文解析は私が多少は重点的に練習していたので解きたいということなどを確認しました。
そんなこんなしているうちにもう開始10分前です。さすがにいつものコンテストと同じように1分前に「ぞい」を呟くのはバタバタしてしまいますが、「ぞい」が早いと他の競プロerから「おもらし」と叩かれてしまいます。気合の入り方は手動と比較して弱くなってしまうのですが、仕方がないので今回は予約「ぞい」で妥協しました。
ぞい!!!
— Lorent (@lorent_kyopro) 2020年11月6日
さて本番開始です。ブラウザの更新ボタンを押すと「database broken」みたいなエラーメッセージが表示されます。チームメイトも同じような状況。さすがにこんなことで今までのICPCに向けた精進・チーム練が水の泡になってしまうのは悲しすぎると思い、負荷を掛けてしまうのは承知で復旧したときにはすぐ問題を見れるように一心不乱に更新ボタンを連打していました。
5分経過した段階で、ふと「これが私たちのチームだけだったらどうしよう」という考えがよぎり、事前メールに書いてあった緊急連絡先に電話すると、繋がりませんでした。きっと他のチームも電話を掛けていたのでしょう。私たちだけではないと思えて、少し安心しました。
開始10分後やっと問題が見れるようになり、担当のB問題を開きましたが、 急なシステム回復でまだ心の準備ができていなかったようで、問題文がなかなか頭に入ってこなくて焦りました。丁寧に、冷静に読み直すと、どうやらUnionFindで順にマージしていって、頂点pを含む木のsizeを出力するだけのようです。実装すると、サンプルが合いません。まずいまずい。Bなんかで時間かけていられるもんか。
ここでnrktさんが「A通りました」と。「おつかれさまです」といいながら内心めちゃくちゃ焦っていました。nrktさんは「とりあえずD読みますね」とのこと。HELPを求めようか迷いましたが、もう一度考え直してみると、既にpと連結な頂点につながっている辺だけ処理すれば良さそう。書き直してサンプルが合い、ファイルを間違えないように慎重に提出するとAC。よかった〜。
「B通りました、xelmephさんCどんな感じですか?」と聞くと、「んー多分いけそう」 のような答えだったので、「じゃあ私もとりあえずDいきますね」と返答し、Dを開く。おっ、構文解析じゃんと、ちょっと嬉しくなる。
(こんなことを言っていたやつがいてですね)
— Lorent (@lorent_kyopro) 2020年10月22日
Dを読んで、とりあえずサンプルを手計算で確認していたのですが、隣のxelmephさんの手が止まっていそう…?あんまり声を掛けすぎても焦りを助長してしまうのでよくないとは思いつつ、「どんな感じですか?HELPいきましょうか?」と聞くと、「 なんか実行が終わらないんだよね」と。
とりあえずCに戻り問題文を読むと、問題設定は非常にシンプルで理解しやすいものでした。「w固定して、残り全探索でいけると思う」とxelmephさんの考察を聞き、間違いなさそうなことを確認。私が問題概要を把握した頃xelmephさんのPCでプログラムの実行が終わったので、提出すると、なんとWA……!正直かなり焦りました。なにせペナが+20分と激重なので。このとき、早解きでは抜けられないなと覚悟していました。
先程の考察で合っているのは確信していたのですが、約数の個数のオーダーがあまりわかりません。ただ計算量を丁寧に見積もっていられるような冷静な状態ではなく、とりあえず数分で実装できそうなアルゴリズムだったので、「私も書いてみますね」と言って爆速で実装をしました。
実装完了しサンプルチェックをします。お…遅い……。サンプルで確か30秒程かかってしまいました。(あとで考えてみると、多分 p/w の約数を再び列挙していたのが原因だと思います。) 一応テストケースをダウンロードし、私のPCで進捗を出力しながらプログラムを実行しますが、終わる気配がありません。
xelmephさんにコードを確認してもらうと、同じことを書いているつもりとのことでしたが、とりあえず私のコードで出力された途中経過とxelmephさん側で出力された値の差異をチェックします。diffコマンドなんてものがあるんですね。私は目視でチェックする気満々でしたので、さすがxelmephさんでした。
どうやら数ケース出力される値が違いそう。しかし私のマシンでの実行は終わりません。
ここでxelmephさんが「並列実行するのでコード送って」と。それだ〜〜〜〜〜〜〜。
私のPCでの出力はもはや微動だにしないうちに、xelmephさんの方では並列実行パワーでテストケース2つとも実行終了し無事AC!本当にほっとしました。我ながらいいリカバーができたと思いますし、さらにxelmephさんの事前準備も活きて、チーム戦の醍醐味を感じました。あと、もしオンラインでやっていたら、こんな連携プレーなかなかできなかっただろうなと思います。
ただ、これ以降はチームでひたすら椅子を温め続けました……。問題ごとに感想を書きます。
D
私とnrktさんはほぼここに張り付いていました。
構文解析パートは簡単。そこをささっと書いて、next_permutationでサンプルが合った、わいわいとしているうちは楽しかったかも。
O(n!) はもちろん無理。階乗のオーダー落とすのは大抵bitDPなんですよねとか考えたが、どうもうまくいかなさそう。
最終的な結果を決めうち?でも例えばSから'A'が出力されるとしてS中に'A'が複数あるときはどれが勝ったことにすればいいんだろう……。(ここの考察をもう少し詰めるべきでしたね)
|S| ≦ 100 で、一つの式は5文字からなるので、最大20程度の式しかなさそう(この評価は間違っていそうです)で、式を評価した結果を220で全探索すればうまくいく?そしてその結果になるような全順序の場合の数を求められればよさそう、bitDPでトポソの数え上げ?どうやるんだっけ…うーん……。
としているうちにタイムアップ。
E
ぱっと見包除で解けそうな感じがするよねという話になったが、結局最後まで分からず。通しているチーム数も少なく、これよりはDのがチャンスがあると思っていました。
F
残り1時間となった頃に、xelmephさんが読んですぐに「Undo可能なUnionFindで辺の重みが小さい順に消去していくだけな気がする」と言っていて、私も少し考えてみると、確かに合っていそうな気がします。その時刻で避難所の候補でなくなったものをチェックする処理を愚直にやると間に合わない気がしましたが、UnionFind木の根だけチェックすればうまく処理できそうという話になりました。xelmephさんに私のライブラリを渡し実装を託すも、最後まで答えが合わず、タイムアップとなってしまいました。
G
私は読んでいません。
H
チラ見程度。
最小包含円とかいうやつなのかな?わかりません。
結果・感想
3完で全体70位でした。

「あと1問の壁」を越えたかったけど、やっぱりその壁は高かったです。コンテスト終了直後、やり切った感じは全くありませんでした。
不甲斐ない成績ではありましたが、名古屋大学では1位で、どうやら国内予選を突破できそうとのことです。よかった……!この数ヶ月間の私たちなりの努力が報われたようで、本当に嬉しかったです。成績に関してくよくよ言ってももう仕方がないですし、予選突破できたことに胸を張っていきたいです。
旧帝勢としてこんな成績で不甲斐ないって気持ちはあるんですが、勝ちは勝ちなので素直に喜んじゃいます
— Lorent (@lorent_kyopro) 2020年11月6日
やった〜〜〜〜〜!!!!!!!!!!
私はオンサイトの大会にいくことが競プロerとしての一つの目標でしたので、アジア地区大会が楽しみでなりません。トップ競プロerの強さを肌で感じたいです。またせっかくの機会ですし、TLでお見かけする競プロerさんとの交流も積極的にしていけたらいいなと思っています。
コンテスタントとしての目標は、「あと1問の壁を越える」こととしておきます。長時間のチーム戦をすると、私たちの実力だと大抵「ここからあと1問解けるかどうか」という状況になってくるんですよね。今までのチーム練や各種の有志コンではなかなかその壁を突破することができなかったですし、今回の国内予選でもそうでした。アジア地区大会までにさらに精進を重ねて、本番では清々しくコンテスト終了を迎えることができたらなと思います。
WUPC2020 参加記
WUPC2020に、ICPCチームメンバーであるxelmephさん(@Xelmh)と2人で参加しました。
私にとっては初めてのチーム戦でしたので、記念に参加記を綴っておきたいと思います。
コンテスト前
同じ大学なのでもちろん地理的な距離も近く、せっかくの機会なので顔合わせも兼ねてオンサイトでチーム戦をしようということになりました。ICPCチームメンバーのもう一人は他の用事が重なってしまったため、今回は2人での参戦に。
まだTwitterとLINEでしか繋がっていない関係性でしたので、駅で待ち合わせをしてちゃんと実在の人間が現れたときはほっとしました。幻覚ではなかったと信じています。
早めにランチを済ませてxelmephさんのお家にお邪魔する予定だったのですが、食後のアイスティーのサーブが遅れ、 お家についたのはコンテスト30分前でした。時間に余裕を持っておいてよかった〜。 若干焦りつつ物理的な環境構築とアカウント作成、登録を済ませ、とりあえず序盤は奇数問を私、偶数問をxelmephさんが読み進めていこうという打ち合わせをしていると、あれよあれよという間にコンテストが開始しました。ICPCはもう少し気持ちの準備をする時間が取れるといいな。
コンテスト中の立ち回り
Aは私が通します。(0:03)
その間にxelmephさんがBの考察を終わらせ提出するもWA。後から提出コードを見るに、0でないという条件を見落としてしまっていたようです。しかし焦らずすぐにリカバー、さすがの冷静沈着さでした。(0:09)
(Bはコンテスト終了後に読んだのですが、私はすぐには解けなかった気がします。)
Cを読んで、考察ノート上でいじくりまわしていたら二項係数が見えてきたので私が実装します。前日にOSのクリーンインストールをして環境構築をし直していたため、modintのスニペットが展開されないバグに襲われ焦りましたが、「mint」と入力して一呼吸待ってからTabを押すとちゃんと出てきました。(これだから重いエディタさんは……。)提出すると無事AC。ふー、一安心。(0:29)
私がCを解き終えてEとGを読んでいた頃、xelmephさんが「J、SCCするだけでは?」と。読み進めるの早いなー。考察を聞いてみると確かに解けそうな気がしてきます。ということで、SCCのライブラリを持っていた私が実装を担当。しかしsample3が合いません。落ち着いてsample3の図を見ると、非連結な島もあるじゃん、ということに気付きます。DSUで予め同じ塊にあるかどうかを判定すればいいのでは、と書いてみると、sampleが合いました。ほっとしながら提出するとなぜかWAを食らう。あれあれ、困りました。(0:46)
2人で固執しても仕方ないと思い、Jの再考察をxelmephさんに任せて私は他の問題を読みにいきます。 ここで順位表を確認すると、Fがかなり解かれている様子。既にFを読んでいるxelmephさん曰く、「ちょっと考えたけど、あんまり見えてこなかった。」とのこと。これは私が解かねばな、と開いて考察。15分ほど考えて、ジャンプできる回数が素因数2の個数と等しくなることは見えてくるも、sample2を見るとジャンプ回数が多い方がいいってわけでもなさそう。うーん。
私のFの考察が行き詰まっていたので、とりあえずここまでの考察をxelmephさんに話して2人で考えていると、ジャンプする回数をすべて試せば良いことに気付きました。やっぱり考えをまとめて人に話すのって大事だなぁと実感。
実装はシンプル、サクサクっと書き上げました。が、最大ケースのsample3が合いません。えぇ…… 。
私がバグに苦しんでいる間に、xelmephさんがJのうまくいかない原因を解明し手直しして再提出するもWA。この辺り、暗雲が立ち込めていましたね。(1:30)
その後もどうもFのバグの原因が私には見つけられなかったので、コードを見せながらxelmephさんに相談すると、「ここって、intでいいの?」と。あああああ!!それだ!!!私はなんてド初心者ムーブをかましてしまったんでしょう……。llに書き換えてさくっとAC。このバグで20分くらい無駄にしました、大変申し訳ありませんでした……。(1:48)
改めて順位表を見にいき、どれを仕留めようか考えます。E、G、J、Mが狙い目っぽい。まだ読んでいなかったMを開くと、問題文に全方位木DPをしてくださいと書いてありました。グラフ問題はxelmephさんの得意分野なのですが、抽象化全方位木DPをライブラリとして持っている私の方がさすがに早く書けるかもと判断し、Mの実装を担当します。
ここでxelmephさんも一旦Jを離れ、Gに移ることに。ただのナップサックDPをした後に、できたDPテーブルを再利用すれば休憩の処理がうまくできそうなことを序盤に見出していたので、その考察を伝えた上であとはお任せしました。
私がMの実装を終えてsampleを試すと、それっぽい値を出力しながらも若干ズレています。xelmephさんに泣きつくと、私の考えた遷移が間違っていることが判明。DPの値と別に、部分木の明るさの合計値も管理しなければいけなさそうなことに気付き、実装し直し。無事ACです。(2:27)
xelmephさんはGの実装をバグらせている様子。私はナップサックDPに対しての苦手意識を未だ払拭できないままなので、頑張れ頑張れと応援するのみ。すみませんでした。
私はMをACした後、Eに向かいました。Nが入る場合と入らない場合で分けてcombinationやらいろいろすれば解けそうだなと思って考察を進めるも、次々と例外パターンが出てきます。この方針じゃうまくいかなさそう……。 xelmephさんに少しEを考えてもらったところ、素因数分解してbitDPできそうとのこと。私には微塵も見えなかった方針でびっくりしちゃいました。
ここでEをxelmephさんに任せ、Gは私にバトンタッチです。Gを改めて考察してみると、曖昧だった休憩の処理方針が鮮明に見えてきました。実装すると、なんと一発でsampleが合いました。あれあれ、もしかして私DP得意かも?と心の中で少し誇らしげに。提出したら一発AC。これは気持ちよかった。(3:39)
これ以降、終了までほとんどの時間をxelmephさんはE、私はJに費やしました。 Jについてですが、SCCしてDAG上でトポソ順にDPすれば、ある頂点に関してそれより上流にある頂点は全部列挙できそうだと思い、bitsetを持たせたDPを書くも、提出前になんとなく予感はしていた通りのMLE。その後もずっと考え続けましたが何も手が出ませんでした。
終了3分前、ついにxelmephさんがEのバグを手元では取りきりsampleを合わせて提出するも、22/33まではACで、23ケース目でRE……うっうっ……。でも粘りがすごかったです。私は隣でうーんうーんと言う機械になってしまっていたので。
そんなこんなでコンテストが終了しました。結果は6完の87位。青コーダー2人のチームとしては不甲斐ない結果となってしまいましたが、初めてのチーム戦、とっても楽しかったのでよしです。

感想・反省
考察がまだ不十分な状態だったとしても、言語化してチームメイトに伝えることによって、自分の考えもまとまってくるし、自分には思いつかなかったアイデアもいただけるしで良い事づくしだなと思いました。ただ、実装している最中はさすがにあまり声をかけすぎないようにした方がいいと反省。3人であれば、1人実装しつつ、他の2人で考察するスタイルはありだなと思いました。
また上述の反省とも繋がるのですが、中終盤は個人戦に専念しすぎず、同じ問題を複数人で考えた方が解ける確率が高いように感じました。今回で言えば、最後EかJのどちらかに2人で挑んでいれば、少なくともあと1問は通せたように思います。
自分用の覚書として書いている部分も大いにあるので書き殴りの文章になってしまいましたが、私の初めての競プロチーム戦参加記は以上です。WUPCの運営の皆さん、このような楽しい機会をご提供いただきありがとうございました。
AtCoderで水色から青色になるまでの日記
8月23日のAtCoder Beginner Contest 177で、念願の青コーダーになることができました。
ついに憧れの青コーダーになれました!!!!!
— Lorent (@lorent_kyopro) 2020年8月29日
まだまだ止まりませんよ〜〜〜
LorentさんのAtCoder Beginner Contest 177での成績:227位
パフォーマンス:2114相当
レーティング:1589→1655 (+66) :)
Highestを更新し、2 級になりました!#AtCoder #ABC177 https://t.co/jLuSO3xvLK pic.twitter.com/I9vH3t1Iw6
私の今回の色変記事は、ただの日記です。
水色から青色になるまでにどういう精進をしてきたのか、何を学んだのかを振り返り、この節目に一度まとめておきたいと思い、ただただ自分のために本記事を書きました。前回の色変記事の執筆目的とは180度異なり、他の競プロerさんに役立ててもらおうという思いでは書いていません。そのような色変記事を期待して読み始めた方には申し訳ございません。
ただ、私自身青色になれた今、青色になるために最も大切なことは、知識を増やすことではなく、水色までに身につけたことの精度・スピードをあげることだと感じています。青色になるために必要なアルゴリズムや精進のTipsが知りたいという方で、私の前回の色変記事を未読の方は、ぜひそちらを読んでいただきたいです。
また自己紹介につきましてはこの記事をお読みください。
今回の色変記事を書くにあたり、水色になったとき(2020/5/3)から青色になる(2020/8/29)までの自分自身のツイートをすべて振り返りました。 一競プロerが水色から青色になるまでの競プロ関連の出来事をもれなく書いたので、興味を持っていただける方は以下本編へどうぞ。
各種精進データ





日記
5月
上旬
- 5月3日にAtCoder水色になりました。
この色変を期に、ブログというものを人生初めて書きました。稚拙な文章ながら頑張って書いたら、たくさんの方から反応をいただけて、競プロコミュニティの幅がぐっと広がったように思います。 Markov Algorithm Onlineにのめり込みそうになりましたが、Test Contestで自身の適性の無さを自覚し引退しました。
精進はあさかつ・よるかつが主軸でした。
わからなかった問題については解説ACも厭わず、すべての問題を通すようにしていました。
学習内容
- multisetの使い方
中旬
セグ木と運命の出会いを果たしました。再帰で書いたらえびちゃんに絡まれました。
これを期にフォローしていただけて、以降たくさんのことをえびちゃんから教わりました。
再帰なしで書けたらびっくりしちゃいませんか?
— えびちゃん (@rsk0315_h4x) 2020年5月11日Twitterで流れてきたDDCC2020の動画を見て、オンサイトへの参加を夢見るようになりました。 (一応)新卒枠なので、オンサイトが開かれると大変嬉しいのですが、今年度はあまり期待しないほうがいいかもなという気持ちもあります。
大学から課せられた膨大な量のレポートに苦しめられつつも、それ以外の時間は夢中で競プロばかりしていました。レポートはどれも、単位がくるであろう最低限クオリティで次々と生成しました。
学習内容
下旬
第3回アルゴリズム実技検定(PAST)を受けたら、70点中級でした。同レート帯のライバルの多くは上級を獲得しており、屈辱を味わいました。必ず第4回でのリベンジを果たします。
Codeforcesで初めて紫になりました。(この後3回ほど反復横跳びをしたのは内緒です。)
こどふぉ、紫になりました!!
— Lorent (@lorent_kyopro) 2020年5月26日
わーい!!! pic.twitter.com/LBQI9QwfFzAtCoderで青精進(RPS 160000)を達成しました。
学習内容
- セグ木の抽象化
- セグ木上の二分探索(再帰)
- Fenwick Tree、二次元Fenwick Tree、Fenwick Tree上の二分探索
- パスカルの三角形上の矩形和の性質
- グラフの頂点倍加テクニック
- Z-algorithm
6月
上旬
VSCode教からEmacs教に改宗し、左手小指を痛めました。
Emacsのキーバインドに慣れるまで、コーディングが一時的にとても遅くなりました。よるかつがなくなったこともあり、あまり朝夜のバチャに参戦しなくなりました。
Rubikunさんの色変記事に感化されて、自分より2つ下の色の問題から全て埋めていこうと決心し、すぐに茶・緑diffを埋めました。問題を解くことに脳のリソースを奪われずに済むので、Emacsの練習にもちょうどよかったです。
AOJ Course埋めにハマりました。学んだデータ構造/アルゴリズム知識をそのまま問われる、教科書の例題のような問題ばかりが並んでいます。
学習内容
- 浮動小数点数の誤差について
- for loopで書くbitDP
中旬
新型コロナウイルスの感染状況が落ち着き、大学の実習が再開となりました。
Emacsのキーバインドが手に染み付いてきて、以前よりもコーディングのスピードが明らかに上がりました。 左手小指の筋力がついてきました。
今までに勉強した知識を用いる問題を解くことよりも、AOJ Courseを埋めるべく、新しくデータ構造/アルゴリズムを学ぶことのほうが楽しくなってきました。
学習内容
下旬
AtCoderの成績が振るわなくなりました。
この間に、ライバル視している人たちにぐんぐん抜かされてしまいました。苦しい時期っぽい pic.twitter.com/PrcVHvrSch
— Lorent (@lorent_kyopro) 2020年6月22日Codeforcesも青色に落ちてしまいました。
水色から青色になるまででいえば、この頃が一番辛い時期であったように思います。同学の競プロerとICPCのチームを組みました。(最近公式からアナウンスがありましたが、当然のように平日開催されるのですね。果たして実習を休むことができるのか不安になってきました……。今度学務に掛け合ってきます。)
学習内容
- 行列累乗
- 形式的べき級数の基礎
- 包除原理
7月
上旬
実習が本格化してきて、コンテストの成績が振るわない中、思うように競プロに時間を割くことができず苦しかったです。
最低限の精進量は確保しようと、くじかつ(Normal) を解説ACしてでも最後まで通すことをノルマとしていました。
通学電車の中でWavelet Matrixの勉強をし、その魔法のような仕組みに魅せられました。
学習内容
- Wavelet Matrixの仕組み
中旬
この頃からくじかつをサボり気味になりました。くじかつが有用でないと判断したという訳ではなく、精進として他にやりたいことが増えた、という理由からです。
ライバルの真似をして、令和ABC-EをGolf以外すべて埋めました。回ごとの難易度差がとても激しかったです。
DPに対する苦手意識を克服しようと、EDPC埋めを始めました。
実習が終わり、夏休みになりました。この夏は競プロに捧げることを誓いました。(就職活動さん……。)
学習内容
- 典型bitDPのパターンを整理
- Convex Hull Trick
- Sparse Table
下旬
水diffをすべて埋めました。「埋める」という精進法の特徴として、どうしても自分の苦手とする問題が残りがちなので、終盤はかなりハードでした。
区間に辺を張るテクニックについての記事を書きました。今まで書いた記事の中で一番多くの方に読んでいただき大変嬉しかったです。
その後、このテクニックの概要を紹介しているブログ記事や、このテクニックが使えるyukicoderの問題解説などに、実装の例としてリンクを貼っていただけました。EDPC埋めを3問(T, W, X)残して終了しました。残り3問は放置してしまっているので、いつかもう一度向き合わねばと思っています。
学習内容
- 区間に辺を張るテクニック
- 配列サイズ2nのセグ木が動く仕組み
- 3nの全探索
- Li-Chao tree(線分対応、非再帰、2n)の自前実装
- 2種のトポロジカルソート(Kahn, Tarjan)の違いについて
- Heavy-Light Decomposition
8月
上旬
Educational Codeforcesバチャを精進の主軸にしようとしましたが、復習キューの消化に思ったより時間がかかりすぎてしまい、休止しました。
ABCで、以前勉強したWavelet Matrixで殴れる典型問が出題されたにも関わらず、コンテスト中にググって出てきた別解法で通すということをしてしまいました。
既に勉強したデータ構造の典型問を自力で解けない自分に悲しくなり、写経で済ませていたWavelet Matrixの自前実装を夏休み中にすることを決意しました。いつも意識している同レート帯のライバルがこの頃からAtCoder青になり始めて、より強く青色に憧れを抱くようになりました。
JOI埋めを始め、まずは難易度1〜5までを埋めました。典型DPの再確認をすることができたように思います。
学習内容
- 平面走査
- Mo's Algorithm
- 基数乱数、法
のRolling Hash
- modintライブラリの書き直し
- ガウスの消去法の実装
中旬
Codeforces Round #664 (Div. 2)で日本人1位、全体10位を獲得しました。
Div.2日本人1位じゃ〜〜
— Lorent (@lorent_kyopro) 2020年8月12日記念撮影です pic.twitter.com/9RAQ0UOPOu
— Lorent (@lorent_kyopro) 2020年8月12日JOI難易度6埋めを終えました。このあたりからなかなか手応えのある問題が増えてきましたが、何とかすべて自力ACで埋めることができました。
Codeforcesで薄橙になりました。はっきり言って上ブレでしかない思うのですが、それでも自分の名前が暖色って嬉しいものですね。
こどふぉ薄橙達成!
— Lorent (@lorent_kyopro) 2020年8月15日
これで私も暖色コーダーを名乗れます✌ pic.twitter.com/apUTmhErzi8月16日から8月19日まで、他のことをほぼ何もせずにひたすらWavelet Matrixの勉強と実装をしました。 実装し終わってverifyできたときの喜びは、コンテストでいい成績を残したときの喜びとはまた質の違う、他の何物にも代え難いものでした。
学習内容
- 全方位木DPの抽象化
- Zobrist Hash
- FFT
- RollbackできるDSU
- Offline Dynamic Connectivity
- Manacher
- Wavelet Matrixの自前実装
- 構築
、クエリ
のRMQ
下旬
JOIの難易度7埋めをひたすら進めました。
学習効率を最大限に高めたいなら解説ACはそれほど厭わないほうがよい、というのが持論なのですが、JOI埋めに関してはAtCoder過去問より問題数が限られているのと、一問たりとも例外なく大変学びの多い問題ばかりであるので、解説ACをしてしまうのがどうも悔しく、何とか自力で解きたいという思いで考え続けました。考察1周目を済ませた段階では16/36しかACできませんでしたが、解けなかった問題について何周も考察を繰り返していくうちに、32/36まで自力ACすることができました。8月29日、ついにAtCoder青色を達成できました。
TLの皆さんからたくさんの祝福をいただき、とても嬉しかったです。また、何とか夏休みの終わりまでに目標を達成することができて、清々しい気持ちでいっぱいです。
学習内容
- セグ木上の二分探索(非再帰)
心がけていること
考察パートと実装パートを切り分ける
これは前回の色変記事にも書いたのですが、再掲です。それだけ重要なことだと考えています。
私がコンテスト中に意識していることとしては、とにかくこれに尽きます。
「焦って曖昧な考察のままコードを書き始めてしまい、実装し終わった後にその解法の欠陥に気付き、結局すべて消す羽目に……。」なんて経験はありませんか?
実装前に考察を詰めておくようにすれば、誤ったコードを無駄に実装してしまう確率は減らせますし、コーナーケースへの注意力も高まります。また、頭を悩ませながら実装するのと、十分な考察の基に実装するのでは、スピードが段違いです。
時々やることを変えてみる、または少し距離を置く
同じことばかりしていれば、誰しも飽きるものです。そんなときは一度、やることを変えてみるとよいです。私は、問題解きたい(今までに学んだデータ構造/アルゴリズムの演習を積みたい)期と新しいデ/アを学びたい期が周期的に訪れるので、その欲求のままに精進をしています。日記の学習内容欄の量を見ると波がわかりやすいかと思います。
競プロをしばらくやらないのも、決して悪いことではありません。といいながら、何となく罪悪感を抱いてしまうのはとっても共感できるのですが……。私も、競プロの対義語であるところの人生が忙しくなってきたときは、少しの間競プロから離れて、どう両立させていくかを毎回模索しています。経験上、しばらく離れてから再開すると、また純粋に競プロを楽しいと思えるようになります。
今後について
日記にも書いた通り、この夏を競プロに捧げて何とか青色まで来ることができました。
しかし今後は大学の実習も再開し、なかなか思うように競プロに時間を割けない日が続きます。今までライバルだと思っていた人たちともぐんぐん差をつけられてしまい、悲しくなることもあるかもしれませんが、他人との比較に囚われすぎることなく、これからも私なりの精進の軸をぶらさずに、可能な範囲でコツコツと取り組んでいきたいと思います。
今後学びたいことリスト
- 遅延セグ木を自前実装
- Segment tree beatsの勉強
- 剰余環の勉強
- DPのオフライン化の勉強
- 線形代数の勉強
- マトロイドの勉強
- フローの勉強
美しいデータ構造/アルゴリズムが大好物なので、推しのデ/アがあるよという方はぜひ教えて下さい! 私の推しは、セグ木とWavelet Matrixです。未履修の方はぜひ学んでみてください。
ここまでお読みいただき、ありがとうございました。
最後に私のポリシーをペタリとしておきます。私が緑だったころのツイートです。
Twitterで交流のある競プロerのみなさん、これからもぜひお互いに切磋琢磨していきましょうね。
みんなで黄色くらいになって、みんなで「緑の頃が懐かしいなあ」って言いたい https://t.co/I2U5zWJ8by
— Lorent (@lorent_kyopro) 2020年4月25日